[2026.05] I have been honored with the UCITE Glennan Fellowship for the 2026-2027 academic year.
[2026.05] 2 papers accepted by ICML 2026.
[2026.04] We recieved the Breaking Boundaries Seed Grant ($15K) at CWRU.
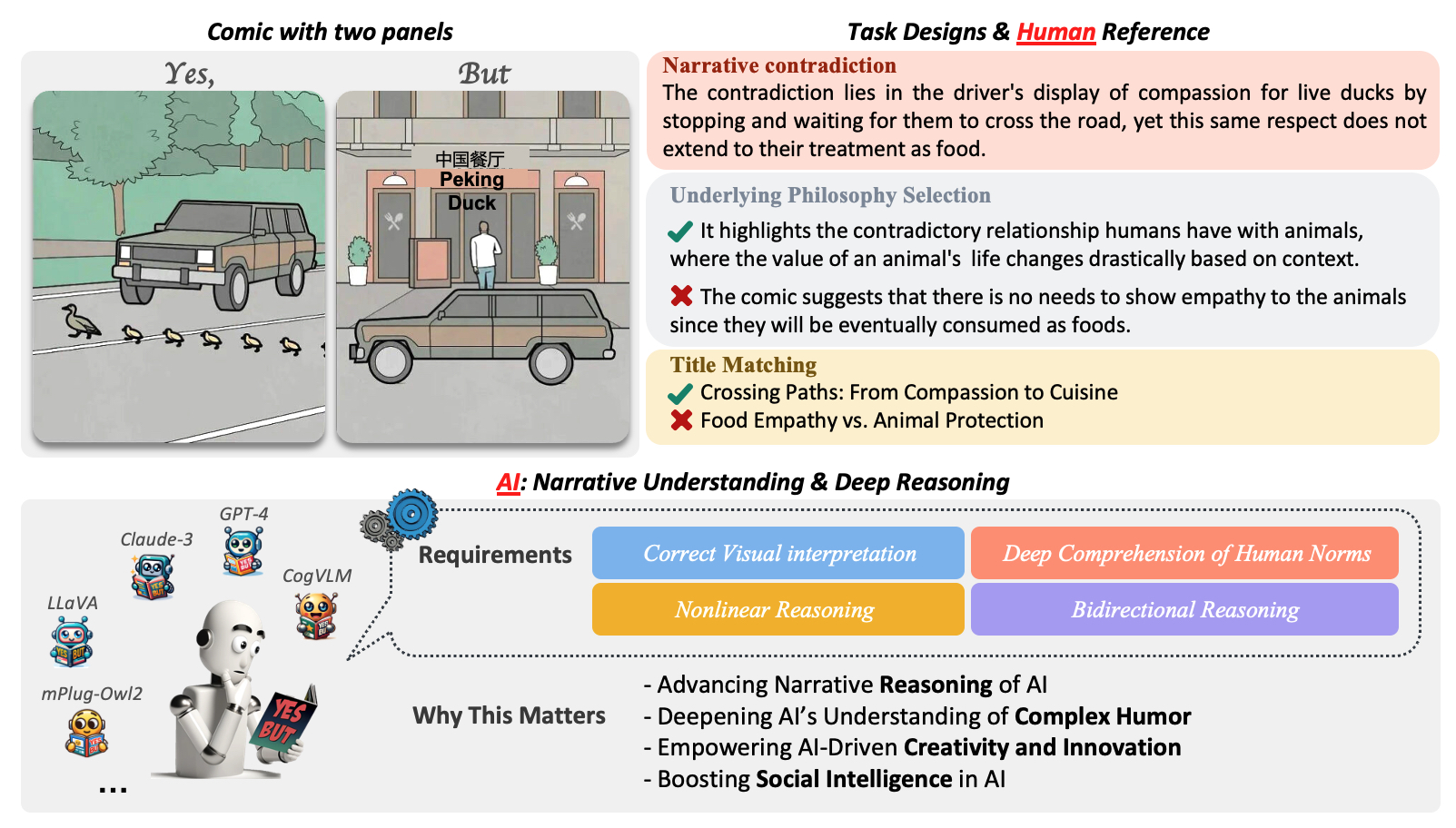
[2026.04] 1 TPAMI paper accepted: When 'Yes' Meets 'But': Can AI Comprehend Contradictory Humor in Comics. The webpage is available here.
[2025.11] Check out our newly released Awesome-Spatial-VLMs github repo and website, a community-maintained companion resource to our survey paper: Spatial Intelligence in Vision-Language Models: A Comprehensive Survey !
[2025.11] 1 papers accepted by AAAI 2026!
[2025.09] We have 3 papers accepted by NeurIPS 2025!
[2025.08] 3 papers accepted by EMNLP 2025 (1 main track + 2 findings).
[2025.05] 1 paper accepted by ACL 2025.
[2025.05] We will organize The 12th IEEE International Workshop on Analysis and Modeling of Faces and Gestures (AMFG) at ICCV 2025.
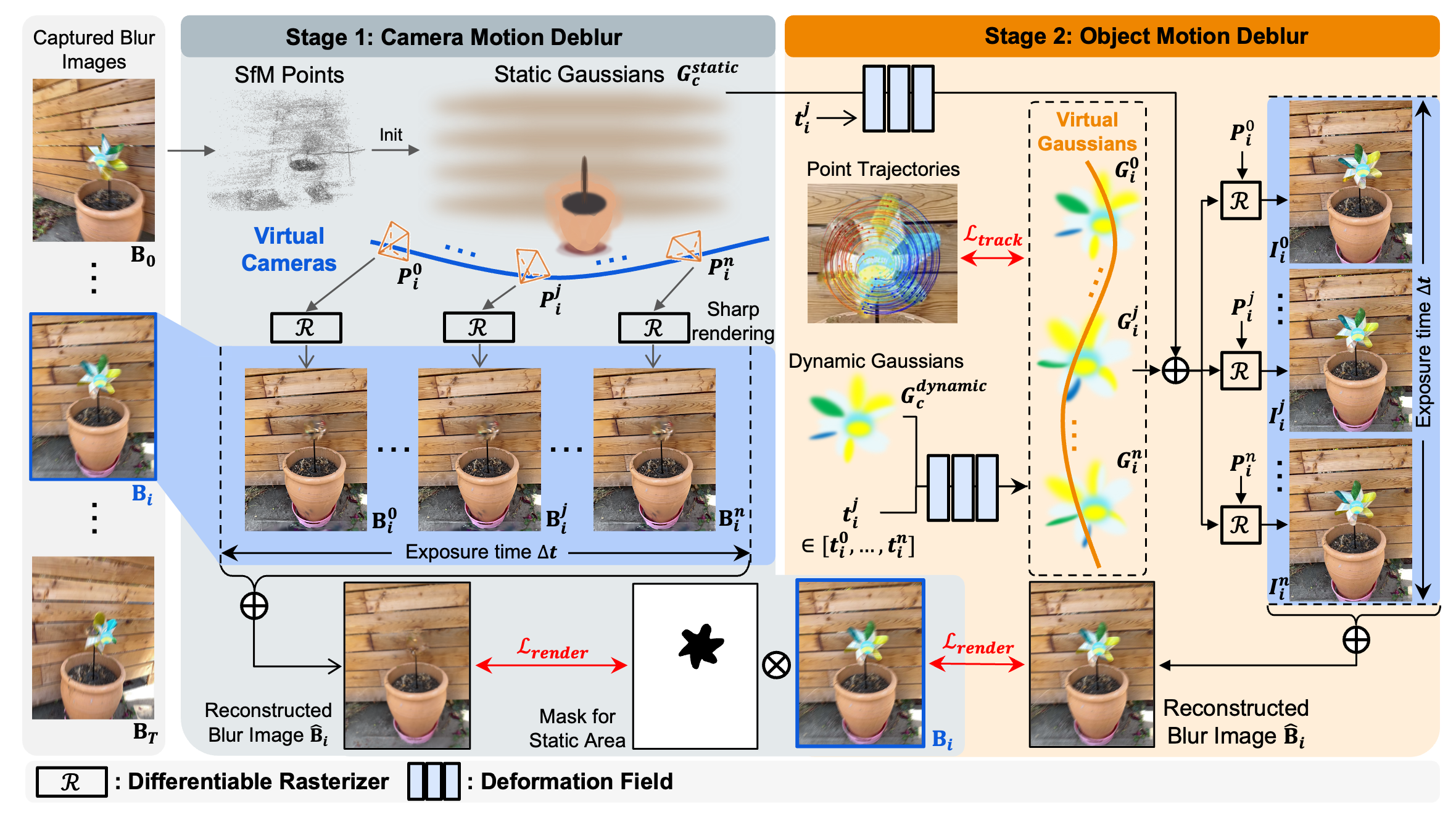
[2025.02] Our paper "Blur-Aware Reconstruction of Dynamic Scenes via Gaussian Splatting" is accepted by CVPR 2025. Congratulations to Yiren!
[2024.12] 1 paper accepted by AAAI 2025.
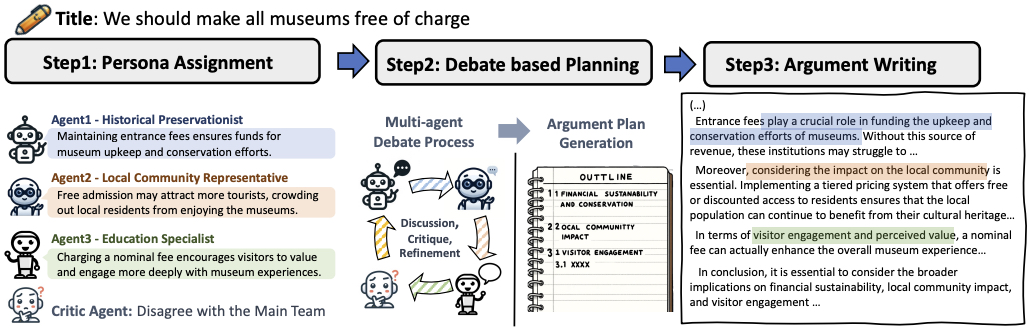
[2024.11] Our paper on multi-agent argument generation has been accepted by COLING 2025.
[2024.09] Our paper Cracking the Code of Juxtaposition has been accepted by NeurIPS 2024 as an Oral!
[2024.09] We have 1 paper accepted by EMNLP 2024.
[2024.08] I recieved the Teaching Award from the Department of Computer and Data Sciences at CWRU.
[2024.07] One paper on 3D scene editing has been accepted by ACM MM 2024.
[2024.07] Our paper on argument generation has been accepted by INLG 2024 (Oral).
[2023.09] Our paper on deepfake detection has been accepted by ICDM 2023.
[2023.05] I will be joining the Department of Computer and Data Science at Case Western Reserve University (CWRU) as a Tenure-Track Assistant Professor from Fall 2023!
[2023.04] We will organize The 11th IEEE International Workshop on Analysis and Modeling of Faces and Gestures (AMFG) at ICCV 2023.
[2023.04] I received the Dissertation Completion Fellowship from Northeastern University.
[2023.02] One paper on 3D face animation ("NeRFInvertor") has been accepted by CVPR 2023. [...] More
Openings: I am continuously looking for highly-motivated Master students and Interns to work on computer vision and machine learning (e.g., 3D vision, VLM, VLA, generative models). Please send me your CV if interested.
More Previous News
[2022.12] Two papers accepted by IEEE Trans. on Image Processing (TIP)!
[2022.07] One paper accepted by ACM MM 2022!
[2022.03] One paper has been accepted by ACM ICMR 2022.
[2022.02] This summer, I will be interning at Microsoft again, working on NeRF models for face animation!
[2021.12] Our paper has been accepted by SDM 2022.
[2021.07] One paper has been accepted by ACM MM 2021 .
[2021.02] I will be joining Microsoft this summer as a research intern focusing on image editing!
[2020.12] Our paper has been accepted by SDM 2021.
[2020.05] Our paper has been accepted by ICDM 2020.
[2020.01] I will be working as a research intern in Zillow's CV group, focusing on floorplan generation to benefit 3D vitual home tours!
[2020.03] We release the code for DA-GAN (accepted by FG 2020) at Github_DA-GAN.
[2020.03] Our paper has been accepted by FG 2020.
[2019.12] We release the code for JASRNet (accepted by AAAI 2020) at Github_JASRNet.
[2019.11] Our paper has been accepted by AAAI 2020.
[2019.08] Our paper is accepted by Expert Systems With Applications (IF: 4.292).
[2019.02] Our paper is accepted by IEEE Journal of Translational Engineering in Healthand Medicine (JTEHM).
[2018.10] Our paper is accepted by IEEE Journal of Translational Engineering in Healthand Medicine (JTEHM).
[2018.06] Our paper is accepted by IJCAI Workshop 2018.
[2017.10] Our paper is accepted by IEEE-NIH Special Topics Conference on Healthcare Innovations and Point-of-Care Technologies (HI-POCT'17).
Biography
I am a tenure-track assistant professor in the Department of Computer & Data Science at Case Western Reserve University.
Before that I received my PH.D. degree in Computer Engineering from Northeastern University in Aug. 2023. During this time, I was under the guidance and supervision of Prof. Yun (Raymond) Fu in the SMILE Lab.
I received my master degree in Electrical & Computer Engineering from Northeastern University in Dec. 2018, and B.E degree from School of Electronic Engineering, Wuhan University of Technology, China, in Jul. 2016. From Fall 2016, I was a member of the Augmented Cogniton (AClab), under the supervision of Prof. Sarah Ostadabbas.
My research interest includes Computer Vision (& 3D Visoin), Multimodal Large Language Models (MLLM), and Embodied AI systems.
Deep Generative Models course (CSDS 570), Case Western Reserve University, USA, 2025-2026 Spring
Computer Vision course (CSDS 465), Case Western Reserve University, USA, 2024 Spring & Fall, 2025 Fall
Special Topics on Generative Models course (CSDS 600), Case Western Reserve University, USA, 2023 Fall
Data Visualization course (EECE 5642), Northeastern University, USA, 2021 Spring
Patents
Yun Fu, Yu Yin, “Frontal Face Synthesis from Low-Resolution Images.” U.S. Patent Application No. 17/156,204.
Yu Yin, Will A. Hutchcroft, Ivaylo Boyadzhiev, Sing Bing Kang, Yujie Li, Pierre Moulon, “Automated Identification And Use Of Building Floor Plan Information.” U.S. Patent Application No. 17/472,527.
Awards
UCITE Glennan Fellowship, Case Western Reserve University, USA, 2026
Breaking Boundaries Seed Grant ($15K), Case Western Reserve University, USA, 2026
Teaching Award, Department of Computer and Data Sciences, Case Western Reserve University, USA, 2024
Aly El Hakie, Yiren Lu, Yu Yin, Michael W. Jenkins, Yehe Liu Conference on Neural Information Processing Systems (NeurIPS), 2025 PaperarXivWebpageCodeDataset
Yao Fu, Xianxuan Long, Runchao Li, Haotian Yu, Mu Sheng, Xiaotian Han, Yu Yin, Pan Li Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025 (Main track) PaperarXiv
Yao Fu, Runchao Li, Xianxuan Long, Haotian Yu, Xiaotian Han, Yu Yin, Pan Li Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025 (Findings track) PaperarXiv
Zhe Hu*, Tuo Liang*, Jing Li, Yiren Lu, Yunlai Zhou, Yiran Qiao, Jing Ma, and Yu Yin
(*co-first author) Conference on Neural Information Processing Systems (NeurIPS), 2024 [Oral] AbstractPaperarXivWebpageCodeDataset
Cracking the Code of Juxtaposition: Can AI Models Understand the Humorous Contradictions
Recent advancements in large multimodal language models have demonstrated remarkable proficiency across a wide range of tasks. Yet, these models still struggle with understanding the nuances of human humor through juxtaposition, particularly when it involves nonlinear narratives that underpin many jokes and humor cues. This paper investigates this challenge by focusing on comics with contradictory narratives, where each comic consists of two panels that create a humorous contradiction. We introduce the YesBut benchmark, which comprises tasks of varying difficulty aimed at assessing AI's capabilities in recognizing and interpreting these comics, ranging from literal content comprehension to deep narrative reasoning. Through extensive experimentation and analysis of recent commercial or open-sourced large (vision) language models, we assess their capability to comprehend the complex interplay of the narrative humor inherent in these comics. Our results show that even state-of-the-art models still lag behind human performance on this task. Our findings offer insights into the current limitations and potential improvements for AI in understanding human creative expressions.
Zhe Hu, Yixiao Ren, Jing Li, and Yu Yin Conference on Empirical Methods in Natural Language Processing (EMNLP), 2024 AbstractPaperarXivWebpageCodeDataset
VIVA: A Benchmark for Vision-Grounded Decision-Making with Human Values
Large vision language models (VLMs) have demonstrated significant potential for integration into daily life, making it crucial for them to incorporate human values when making decisions in real-world situations. This paper introduces VIVA, a benchmark for VIsion-grounded decision-making driven by human VAlues. While most large VLMs focus on physical-level skills, our work is the first to examine their multimodal capabilities in leveraging human values to make decisions under a vision-depicted situation. VIVA contains 1,240 images depicting diverse real-world situations and the manually annotated decisions grounded in them. Given an image there, the model should select the most appropriate action to address the situation and provide the relevant human values and reason underlying the decision. Extensive experiments based on VIVA show the limitation of VLMs in using human values to make multimodal decisions. Further analyses indicate the potential benefits of exploiting action consequences and predicted human values.
Yiren Lu, Jing Ma, and Yu Yin ACM International Conference on Multimedia (ACM MM), 2024 AbstractPaperarXivWebpage
View-consistent Object Removal in Radiance Fields
Radiance Fields (RFs) have emerged as a crucial technology for 3D scene representation, enabling the synthesis of novel views with remarkable realism. However, as RFs become more widely used, the need for effective editing techniques that maintain coherence across different perspectives becomes evident. Current methods primarily depend on per-frame 2D image inpainting, which often fails to maintain consistency across views, thus compromising the realism of edited RF scenes. In this work, we introduce a novel RF editing pipeline that significantly enhances consistency by requiring the inpainting of only a single reference image. This image is then projected across multiple views using a depth-based approach, effectively reducing the inconsistencies observed with per-frame inpainting. However, projections typically assume photometric consistency across views, which is often impractical in real-world settings. To accommodate realistic variations in lighting and viewpoint, our pipeline adjusts the appearance of the projected views by generating multiple directional variants of the inpainted image, thereby adapting to different photometric conditions. Additionally, we present an effective and robust multi-view object segmentation approach as a valuable byproduct of our pipeline. Extensive experiments demonstrate that our method significantly surpasses existing frameworks in maintaining content consistency across views and enhancing visual quality.
Zhe Hu, Hou Pong Chan, and Yu Yin ACL International Natural Language Generation Conference (INLG), 2024 [Oral] AbstractPaperarXivSlides
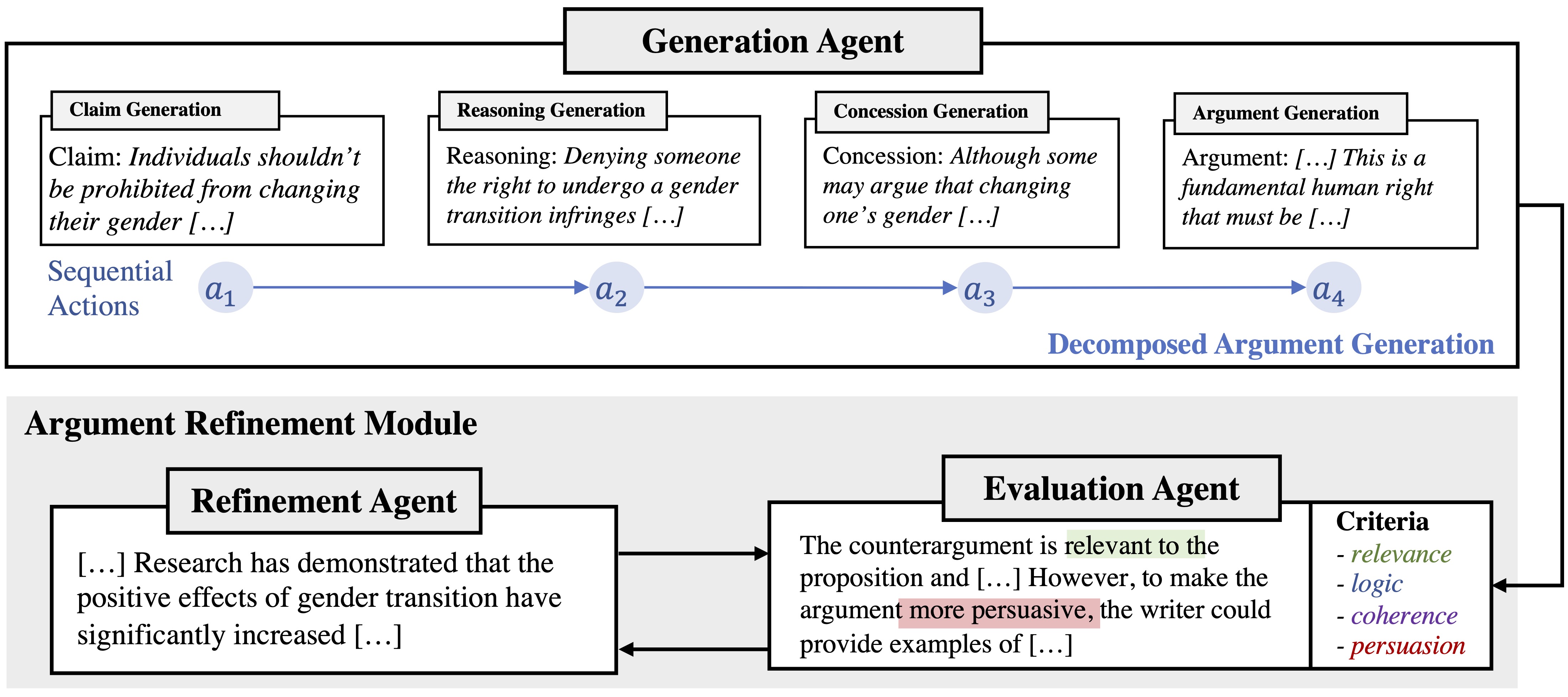
AMERICANO: Argument Generation with Discourse-driven Decomposition and Multi-agent Interaction
Argument generation is a challenging task in natural language processing, which requires rigorous reasoning and proper content organization. Inspired by recent chain-of-thought prompting that breaks down a complex task into intermediate steps, we propose AMERICANO, a novel framework with agent interaction for argument generation. Our approach decomposes the generation process into sequential actions grounded on argumentation theory, which first executes actions sequentially to generate argumentative discourse components, and then produces a final argument conditioned on the components. To further mimic the human writing process and improve the left-to-right generation paradigm of current autoregressive language models, we introduce an argument refinement module which automatically evaluates and refines argument drafts based on feedback received. We evaluate our framework on the task of counterargument generation using a subset of Reddit/CMV dataset. The results show that our method outperforms both end-toend and chain-of-thought prompting methods and can generate more coherent and persuasive arguments with diverse and rich contents.
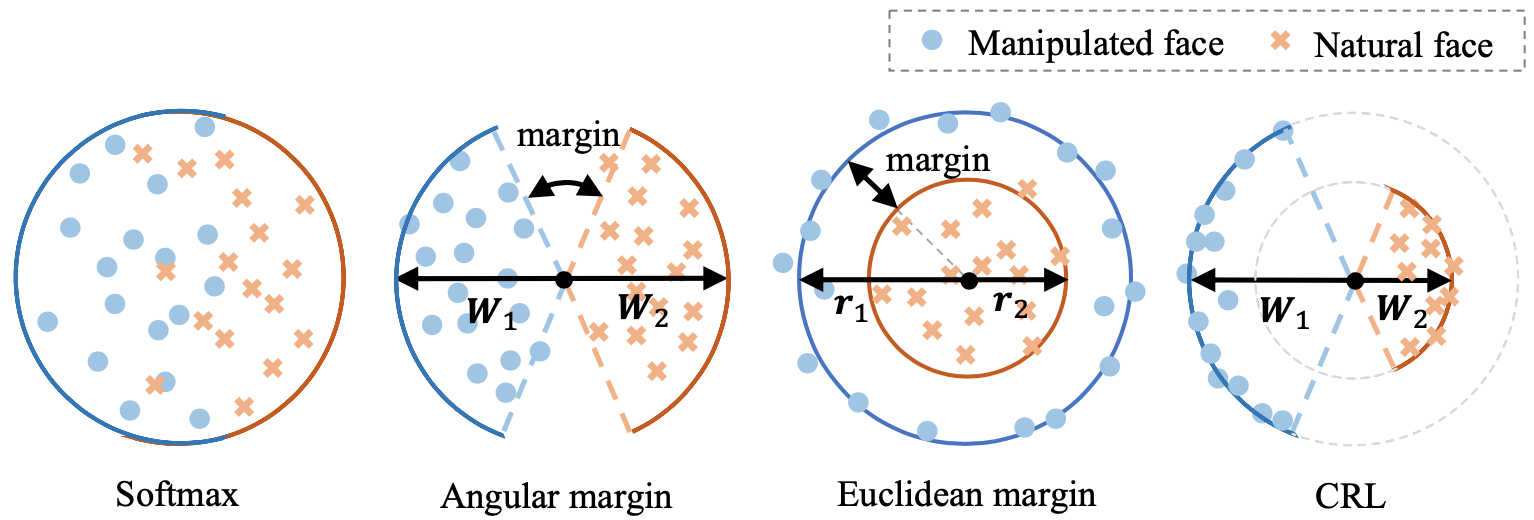
Yu Yin, Yue Bai, Yizhou Wang, and Yun Fu IEEE International Conference on Data Mining (ICDM), 2023 AbstractPaper
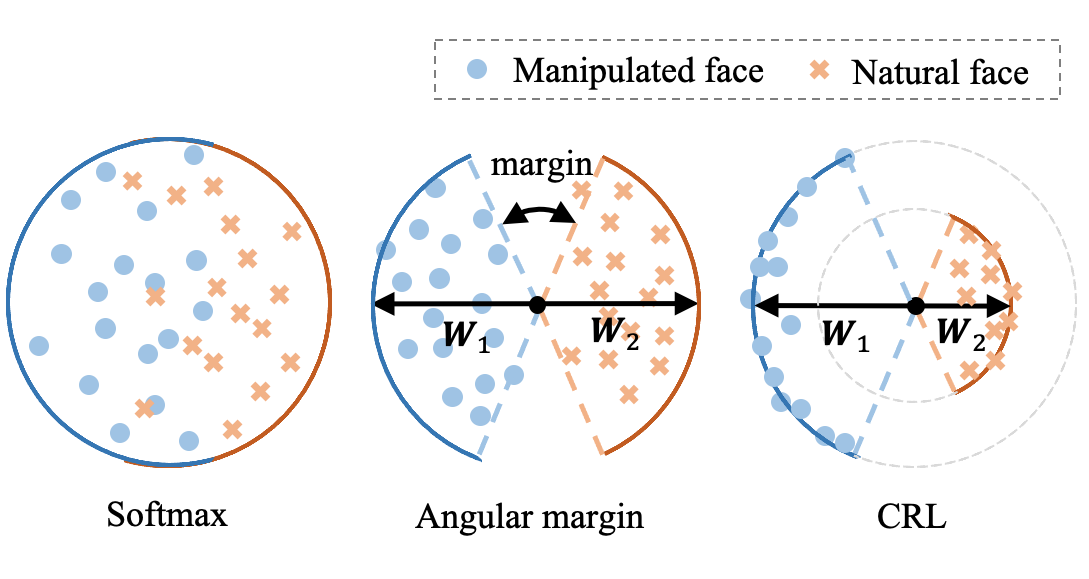
Concentric Ring Loss for Face Forgery Detection
Due to growing societal concerns about indistinguishable deepfake images, face forgery detection has received an increasing amount of interest in computer vi- sion. Since the differences between actual and fake images are frequently small, improving the discriminative ability of learnt features is one of the primary prob- lems in deepfake detection. In this paper, we propose a novel Concentric Ring Loss (CRL) to encourage the model to learn intra-class compressed and inter-class separated features. Specifically, we independently add margin penalties in angu- lar and Euclidean space to force a more significant margin between real and fake images, and hence encourage better discriminating performance. Compared to softmax loss, CRL explicitly encourages intra-class compactness and inter-class separability. Extensive experiments demonstrate the superiority of our methods over multiple datasets. We show that CRL consistently outperforms the state-of- the-art by a large margin.
Yu Yin, Kamran Ghasedi, HsiangTao Wu, Jiaolong Yang, Xin Tong, and Yun Fu IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR), 2023 AbstractPaperarXivWebpageDemoCode
NeRFInvertor: High Fidelity NeRF-GAN Inversion for Single-shot Real Image Animation
Nerf-based Generative models have shown impressive capacity in generating high-quality images with consistent 3D geometry. Despite successful synthesis of fake identity images randomly sampled from latent space, adopting these models for generating face images of real subjects is still a challenging task due to its so-called inversion issue. In this paper, we propose a universal method to surgically fine-tune these NeRF-GAN models in order to achieve high-fidelity animation of real subjects only by a single image. Given the optimized latent code for an out-of-domain real image, we employ 2D loss functions on the rendered image to reduce the identity gap. Furthermore, our method leverages explicit and implicit 3D regularizations using the in-domain neighborhood samples around the optimized latent code to remove geometrical and visual artifacts. Our experiments confirm the effectiveness of our method in realistic, high-fidelity, and 3D consistent animation of real faces on multiple NeRF-GAN models across different datasets.
Yu Yin, Kamran Ghasedi, HsiangTao Wu, Jiaolong Yang, Xin Tong, and Yun Fu
Under review, 2022 AbstractarXiv
Expanding the Latent Space of StyleGAN for Real Face Editing
Recently, a surge of face editing techniques have been proposed to employ the pretrained StyleGAN for semantic manipulation. To successfully edit a real image, one must first convert the input image into StyleGAN’s latent variables. However, it is still challenging to find latent variables, which have the capacity for preserving the appearance of the input subject (\emph{e.g.} identity, lighting, hairstyles) as well as enabling meaningful manipulations. In this paper, we present a method to expand the latent space of StyleGAN with additional content features to break down the trade-off between low-distortion and high-editability. Specifically, we proposed a two-branch model, where the style branch first tackles the entanglement issue by the sparse manipulation of latent codes, and the content branch then mitigates the distortion issue by leveraging the content and appearance details from the input image. We confirm the effectiveness of our method using extensive qualitative and quantitative experiments on real face editing and reconstruction tasks.
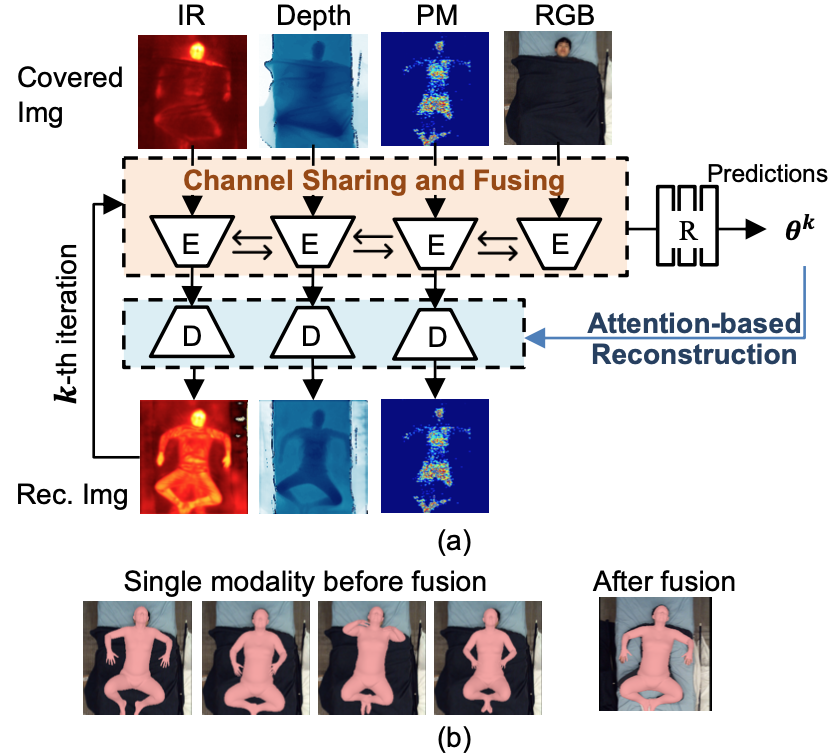
Yu Yin, Joseph P. Robinson, and Yun Fu ACM International Conference on Multimedia (ACM MM), 2022 AbstractPaper
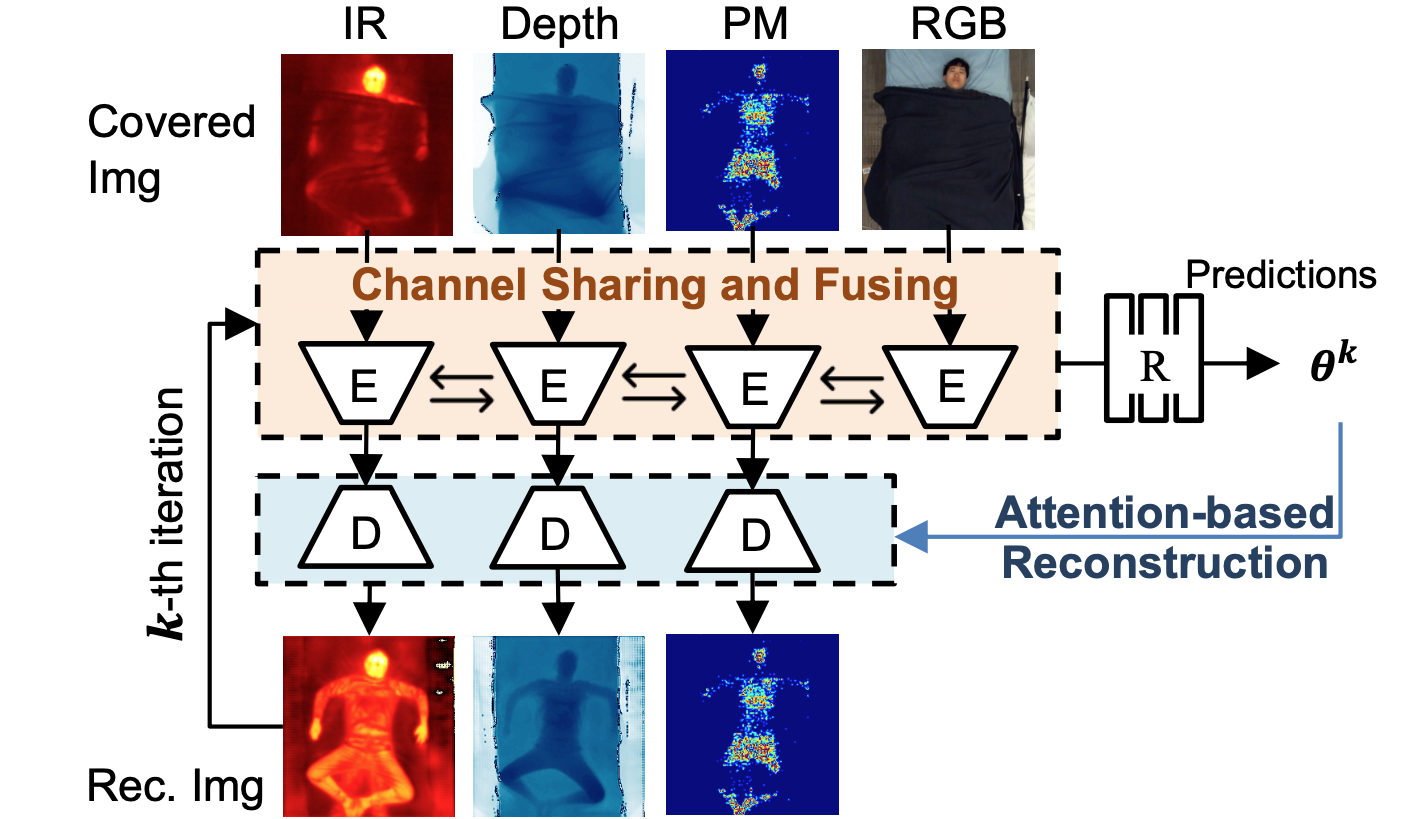
Multimodal In-bed 3D Pose and Shape Estimation under the Blankets
Advancing technology to monitor our bodies and behavior while sleeping and resting are essential for healthcare. However, keen challenges arise from our tendency to rest under blankets. We present a multimodal approach to uncover the subjects and view bodies at rest without the blankets obscuring the view. For this, we introduce a channel-based fusion scheme to effectively fuse differ- ent modalities in a way that best leverages the knowledge captured by the multimodal sensors, including visual- and non-visual-based. The channel-based fusion scheme enhances the model’s flexibility in the input at inference: one-to-many input modalities required at test time. Nonetheless, multimodal data or not, detecting humans at rest in bed is still a challenge due to the extreme occlusion when covered by a blanket. To mitigate the negative effects of blanket occlusion, we use an attention-based reconstruction module to explicitly reduce the uncertainty of occluded parts by generating uncovered modalities, which further update the current estimation via a cyclic fashion. Extensive experiments validate the proposed model’s superiority over others.
Yu Yin, Will Hutchcroft, Naji Khosravan, Ivaylo Boyadzhiev, Yun Fu, and Sing Bing Kang ACM International Conference on Multimedia Retrieval (ACM ICMR), 2022 AbstractPaperPresentation
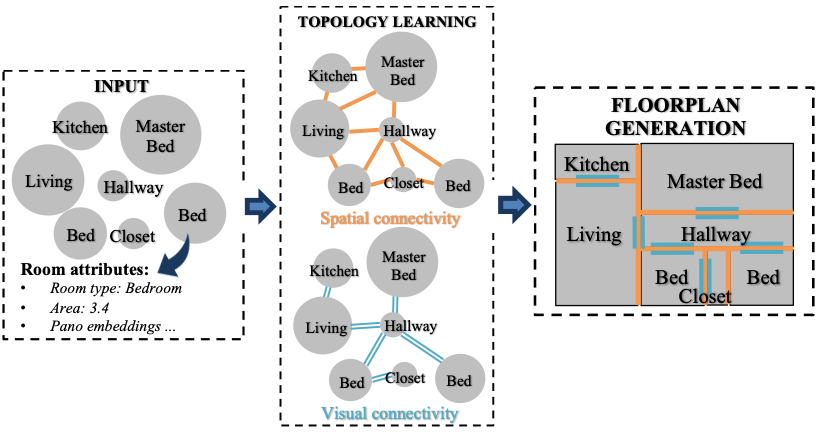
Generating Topological Structure of Floorplans from Room Attributes
Analysis of indoor spaces requires topological information. In this paper, we propose to extract topological information from room attributes using what we call Iterative and adaptive graph Topol- ogy Learning (ITL). ITL progressively predicts multiple relations between rooms; at each iteration, it improves node embeddings, which in turn facilitates generation of a better topological graph structure. This notion of iterative improvement of node embeddings and topological graph structure is in the same spirit as [5]. However, while [5] computes the adjacency matrix based on node similarity, we learn the graph metric using a relational decoder to extract room correlations. Experiments using a new challenging indoor dataset validate our proposed method. Qualitative and quantitative evaluation for layout topology prediction and floorplan generation applications also demonstrate the effectiveness of ITL.
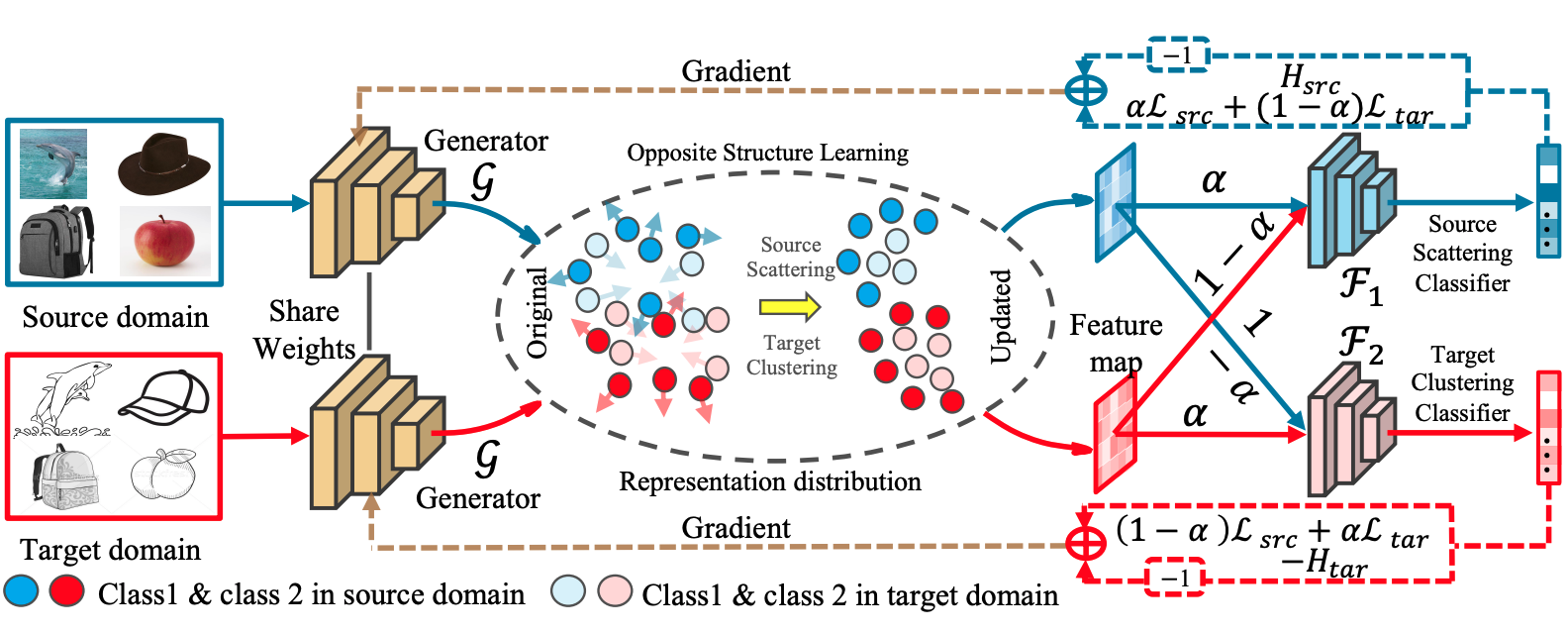
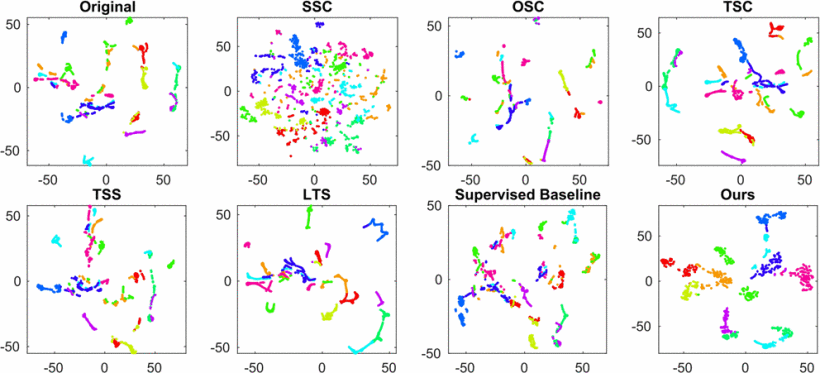
Semi-supervised domain adaptation (SSDA) is quite a challenging problem requiring methods to overcome both 1) overfitting towards poorly annotated data and 2) distribution shift across domains. Unfortunately, a simple combination of domain adaptation (DA) and semi-supervised learning (SSL) methods often fail to address such two objects because of training data bias towards labeled samples. In this paper, we introduce an adaptive structure learning method to regularize the cooperation of SSL and DA. Inspired by the multi-views learning, our proposed framework is composed of a shared feature encoder network and two classifier networks, trained for contradictory purposes. Among them, one of the classifiers is applied to group target features to improve intra-class density, enlarging the gap of categorical clusters for robust representation learning. Meanwhile, the other classifier, serviced as a regularizer, attempts to scatter the source features to enhance the smoothness of the decision boundary. The iterations of target clustering and source expansion make the target features being well-enclosed inside the dilated boundary of the corresponding source points. For the joint address of cross-domain features alignment and partially labeled data learning, we apply the maximum mean discrepancy (MMD) distance minimization and self-training (ST) to project the contradictory structures into a shared view to make the reliable final decision. The experimental results over the standard SSDA benchmarks, including DomainNet and Office- home, demonstrate both the accuracy and robustness of our method over the state-of-the-art approaches.
Yue Bai, Zhiqiang Tao, Lichen Wang, Sheng Li, Yu Yin, and Yun Fu SIAM International Conference on Data Mining (SDM), 2022 AbstractPaper
Collaborative Attention Mechanism for Multi-Modal Time Series Classification
Multi-modal time series classification (MTC) uses comple- mentary information from different modalities to improve the learning performance. Obtaining informative modality- specific representation plays an essential role in MTC. At- tention mechanism has been widely adopted as an effective strategy for discovering discriminative cues underlying tem- poral data. However, most existing MTC methods only uti- lize attention to balance the feature weights within or cross modalities but ignore digging latent patterns from mutual- support information in attention space. Specifically, the attention distributions are different for multiple modalities which are supportive and instructional with each other. To this end, we propose a collaborative attention mechanism (CAM) for MTC based on a novel perspective to utilize attention module. CAM detects the attention differences among multi-modal time series, and adaptively integrates different attention information to benefit each other. We extend the long short-term memory (LSTM) to a Mutual-Aid RNN (MAR) for multi-modal collaboration. CAM takes advantages of modality-specific attention to guide another modality and discover potential information which is hard to be explored by itself. It paves a novel way of employing attention to enhance the capacity of multi-modal represen- tations. Extensive experiments on four multi-modal time series datasets illustrate the CAM effectiveness to improve the single-modal and also boost multi-modal performances.
Yu Yin, Joseph P. Robinson, Songyao Jiang, Yue Bai, Can Qin, and Yun Fu ACM International Conference on Multimedia (ACM MM), 2021 AbstractPaperCodeSupplements
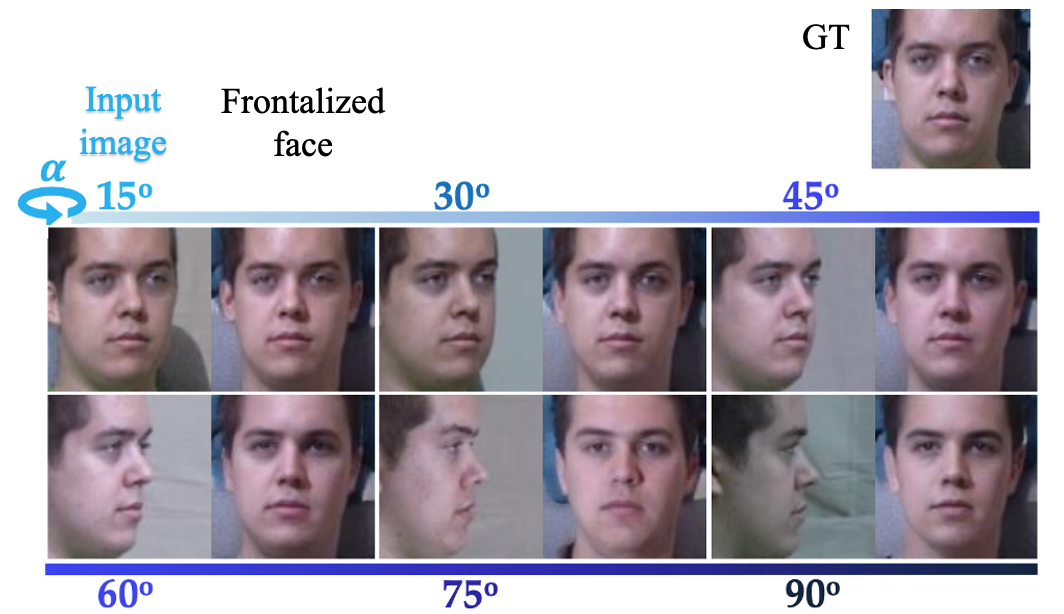
SuperFront: From Low-resolution Image to High-resolution Frontal Face Sythesis
Even the most impressive achievement in frontal face synthesis is challenged by large poses and low-quality data given one single side-view face. We propose a synthesizer called SuperFront GAN (SF-GAN) to accept one or more low-resolution (LR) faces at the input to then output a high-resolution (HR) frontal face with various poses and such to preserve identity information. SF-GAN includes intra-class and inter-class constraints, which allow it to learn an identity-preserving representation from multiple LR faces in an improved, comprehensive manner. We adopt an orthogonal loss as the intra-class constraint that diversifies the learned feature-space per subject. Hence, each sample is made to complement the others to its max ability. Additionally, a triplet loss is used as the inter-class constraint: it improves the discriminative power of the new representation, which, hence, maintains the identity information. Furthermore, we integrate a super-resolution (SR) side-view module as part of the SF-GAN to help preserve the finer details of HR side-views. This helps the model reconstruct the high-frequency parts of the face (i.e. periocular region, nose, and mouth regions). Quantitative and qualitative results demonstrate the superiority of SF-GAN. SF-GAN holds promise as a pre-processing step to normalize and align faces before passing to CV system for processing.
Can Qin, Lichen Wang, Qianqian Ma, Yu Yin, Huan Wang, and Yun Fu SIAM International Conference on Data Mining (SDM), 2021 AbstractPaperCode
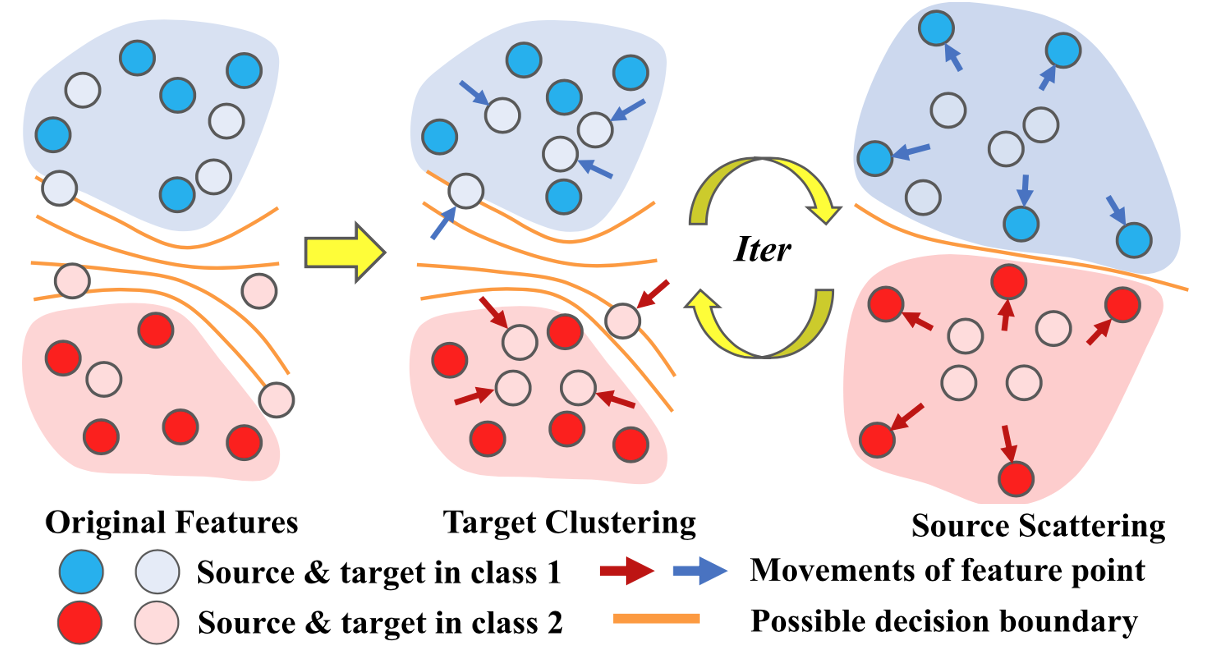
Opposite Structure Learning for Semi-supervised Domain Adaptation
Current adversarial adaptation methods attempt to align the cross-domain features, whereas two challenges remain unsolved: 1) the conditional distribution mismatch and 2) the bias of the decision boundary towards the source domain. To solve these challenges, we propose a novel framework for semi-supervised domain adaptation by unifying the learning of opposite structures (UODA). UODA consists of a generator and two classifiers (i.e., the sourcescattering classifier and the target-clustering classifier), which are trained for contradictory purposes. The target-clustering classifier attempts to cluster the target features to improve intra-class density and enlarge inter-class divergence. Meanwhile, the source-scattering classifier is designed to scatter the source features to enhance the decision boundary’s smoothness. Through the alternation of source-feature expansion and target-feature clustering procedures, the target features are well-enclosed within the dilated boundary of the corresponding source features. This strategy can make the cross-domain features to be precisely aligned against the source bias simultaneously. Moreover, to overcome the model collapse through training, we progressively update the measurement of feature’s distance and their representation via an adversarial training paradigm. Extensive experiments on the benchmarks of DomainNet and Office-home datasets demonstrate the superiority of our approach over the state-of-the-art methods.
Yu Yin, Songyao Jiang, Joseph P. Robinson, and Yun Fu IEEE International Conference on Automatic Face and Gesture Recognition (FG), 2020 AbstractPaperPaperCodePresentation
Dual-Attention GAN for Large-Pose Face Frontalization
Face frontalization provides an effective and effi- cient way for face data augmentation and further improves the face recognition performance in extreme pose scenario. Despite recent advances in deep learning-based face synthesis ap- proaches, this problem is still challenging due to significant pose and illumination discrepancy. In this paper, we present a novel Dual-Attention Generative Adversarial Network (DA-GAN) for photo-realistic face frontalization by capturing both contextual dependencies and local consistency during GAN training. Specifically, a self-attention-based generator is introduced to integrate local features with their long-range dependencies yielding better feature representations, and hence generate faces that preserves identities better, especially for larger pose angles. Moreover, a novel face-attention-based discriminator is applied to emphasize local features of face regions, and hence reinforce the realism of synthetic frontal faces. Guided by semantic segmentation, four independent discriminators are used to distinguish between different aspects of a face (i.e., skin, keypoints, hairline, and frontalized face). By introducing these two complementary attention mechanisms in generator and discriminator separately, we can learn a richer feature representation and generate identity preserving inference of frontal views with much finer details (i.e., more accurate facial appearance and textures) comparing to the state-of-the-art. Quantitative and qualitative experimental results demonstrate the effectiveness and efficiency of our DA-GAN approach.
Yu Yin, Joseph P. Robinson, Yulun Zhang, and Yun Fu AAAI Conference on Artificial Intelligence (AAAI), 2020 AbstractPaperCode
Joint Super-Resolution and Alignment of Tiny Faces
Super-resolution (SR) and landmark localization of tiny faces are highly correlated tasks. On the one hand, landmark lo- calization could obtain higher accuracy with faces of high- resolution (HR). On the other hand, face SR would benefit from prior knowledge of facial attributes such as landmarks. Thus, we propose a joint alignment and SR network to si- multaneously detect facial landmarks and super-resolve tiny faces. More specifically, a shared deep encoder is applied to extract features for both tasks by leveraging complementary information. To exploit representative power of the hierarchi- cal encoder, intermediate layers of a shared feature extraction module are fused to form efficient feature representations. The fused features are then fed to task-specific modules to de- tect landmarks and super-resolve face images in parallel. Ex- tensive experiments demonstrate that the proposed model sig- nificantly outperforms the state-of-the-art in both landmark localization and SR of faces. We show a large improvement for landmark localization of tiny faces (i.e., 16 × 16). Fur- thermore, the proposed framework yields comparable results for landmark localization on low-resolution (LR) faces (i.e., 64 × 64) to existing methods on HR (i.e., 256 × 256). As for SR, the proposed method recovers sharper edges and more details from LR face images than other state-of-the-art meth- ods, which we demonstrate qualitatively and quantitatively.
Yue Bai, Lichen Wang, Yunyu Liu, Yu Yin, and Yun Fu IEEE International Conference on Data Mining (ICDM), 2020 AbstractPaper
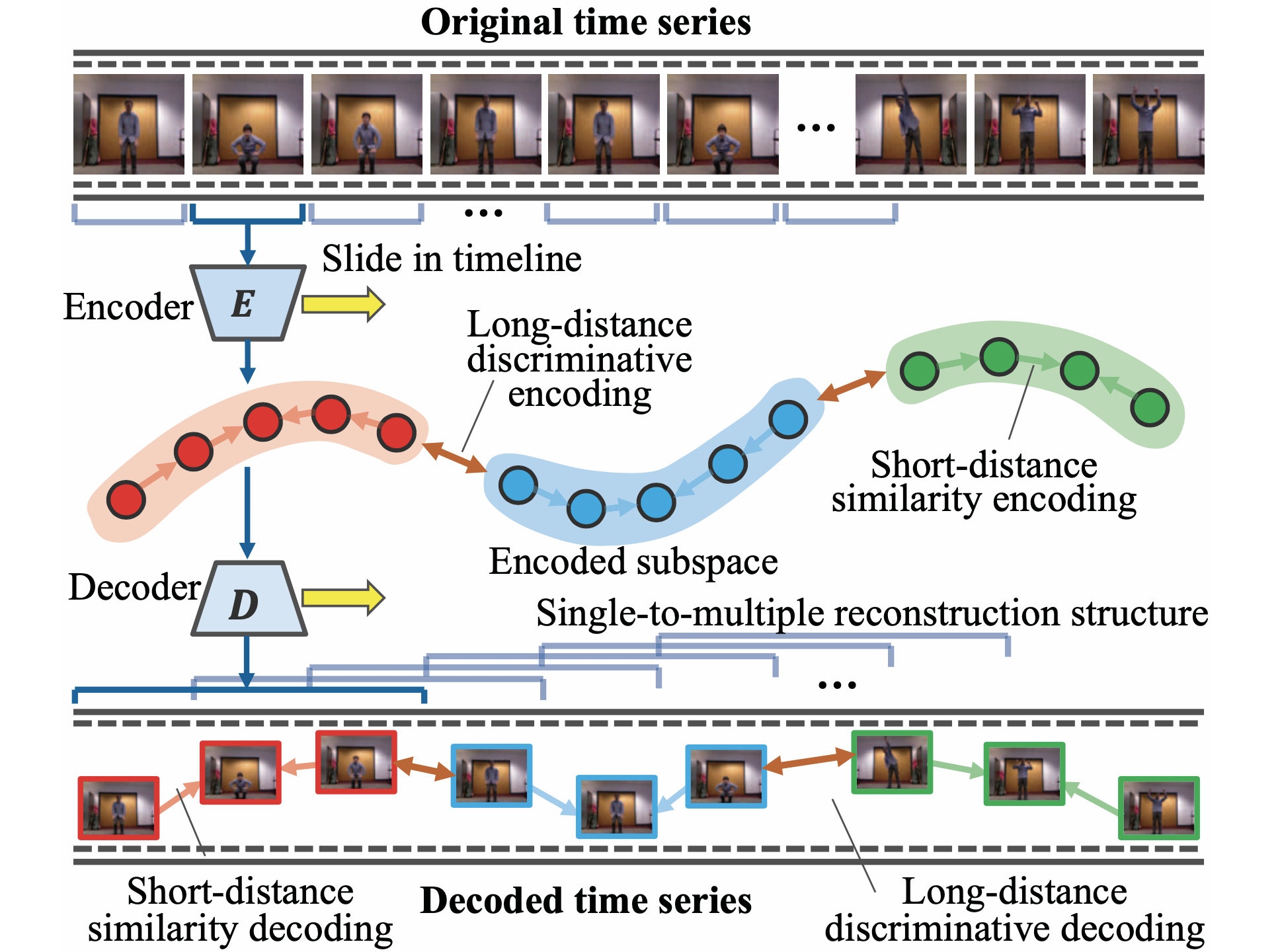
Dual-Side Auto-Encoder for High-Dimensional Time Series Segmentation
High-dimensional time series segmentation aims to segment a long temporal sequence into several short and meaningful subsequences. The high-dimensionality makes it challenging due to the complicated correlations among the sequential features. A large number of labeled data is required in existing supervised methods, and unsupervised methods mainly deploy clustering approaches, which are sensitive to outliers and hard to guarantee high performance. Also, most existing methods mainly rely on hand-craft features to deal with regular time series segmentation and achieve promising results. However, these approaches cannot effectively handle high-dimensional time series and will result in a high computational cost. In our work, we propose a novel unsupervised representation learning framework called Dual-Side Auto-Encoder (DSAE). It mainly focuses on high-dimensional time series segmentation by effectively capturing the temporal correlative patterns. Specifically, a single-to-multiple auto-encoder is designed to capture local sequential information. Besides, a long-shot distance encoding strategy is proposed. It aims to explicitly guide the learning process to obtain distinctive representations for segmentation. Furthermore, the long-short distance strategy is also executed in the decoded feature space, which implicitly directs the representation learning. Substantial experiments on six datasets illustrate the model effectiveness.
Yu Yin, Mohsen Nabian, Miolin Fan, ChunAn Chou, Maria Gendron, and Sarah Ostadabbas Affective Computing Workshop of the International Joint Conferences on Artificial Intelligence (IJCAI Workshop), 2018 AbstractarXivCodeDemoSlides
Facial Expression and Peripheral Physiology Fusion to Decode Individualized Affective Experience
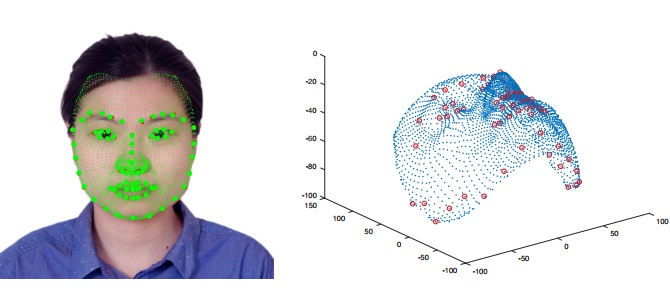
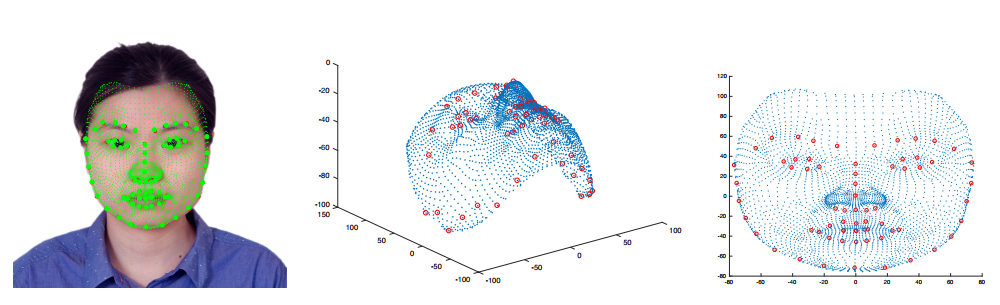
In this paper, we present a multimodal approach to simultaneously analyze facial movements and several peripheral physiological signals to decode individualized affective experiences under positive and negative emotional contexts, while considering their personalized resting dynamics. We propose a person-specific recurrence network to quantify the dynamics present in the person's facial movements and physiological data. Facial movement is represented using a robust head vs. 3D face landmark localization and tracking approach, and physiological data are processed by extracting known attributes related to the underlying affective experience. The dynamical coupling between different input modalities is then assessed through the extraction of several complex recurrent network metrics. Inference models are then trained using these metrics as features to predict individual's affective experience in a given context, after their resting dynamics are excluded from their response. We validated our approach using a multimodal dataset consists of (i) facial videos and (ii) several peripheral physiological signals, synchronously recorded from 12 participants while watching 4 emotion-eliciting video-based stimuli. The affective experience prediction results signified that our multimodal fusion method improves the prediction accuracy up to 19% when compared to the prediction using only one or a subset of the input modalities. Furthermore, we gained prediction improvement for affective experience by considering the effect of individualized resting dynamics.
Yu Yin*, Mohsen Nabian*, Athena Nouhi*, and Sarah Ostadabbas (* equal contribution) IEEE-NIH Special Topics Conference on Healthcare Innovations and Point-of-Care Technologies (HI-POCT), 2017 AbstractPDFMatlab CodePoster
A Biosignal-Specific Processing Tool for Machine Learning and Pattern Recognition.
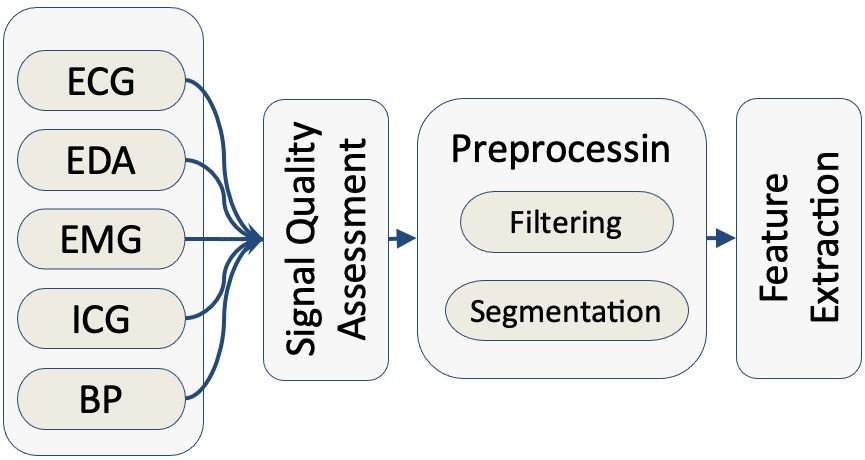
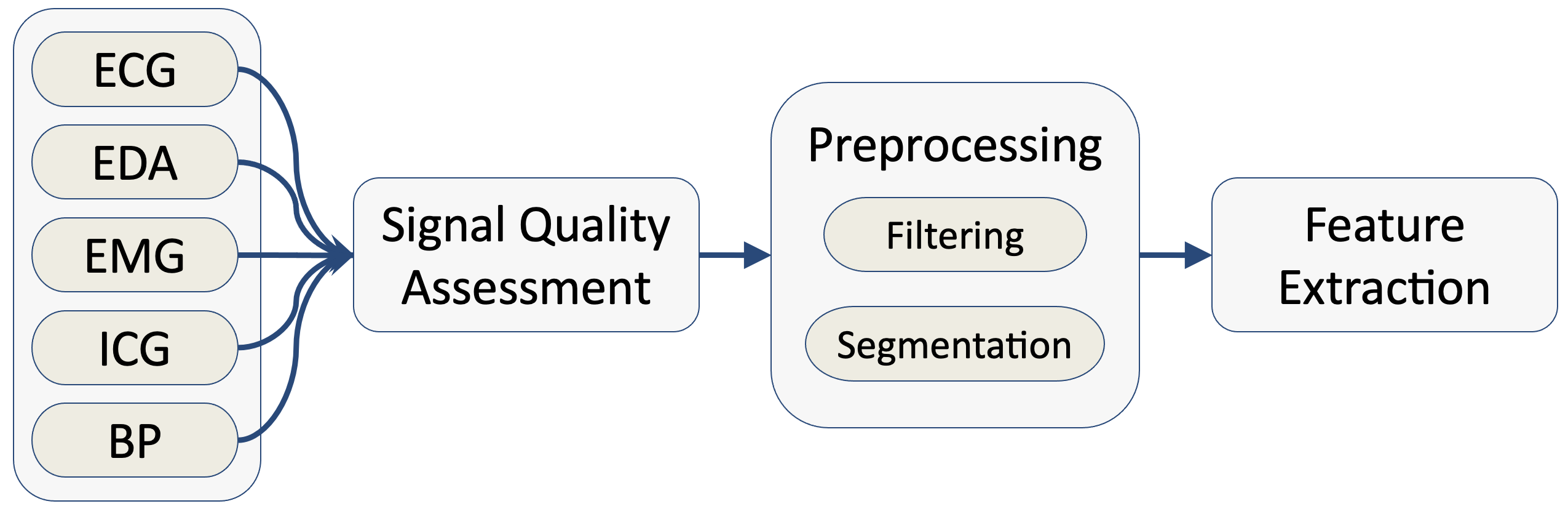
Electrocardiogram (ECG), Electrodermal Activity (EDA), Electromyogram (EMG) and Impedance Cardiography (ICG) are among physiological signals widely used in various biomedical applications including health tracking, sleep quality assessment, early disease detection/diagnosis and human affective state recognition. This paper presents the development of a biosignal-specific processing and feature extraction tool for analyzing these physiological signals according to the state-ofthe-art studies reported in the scientific literature. This tool is intended to assist researchers in machine learning and pattern recognition to extract feature matrix from these bio-signals automatically and reliably. In this paper, we provided the algorithms used for the signal-specific filtering and segmentation as well as extracting features that have been shown highly relevant to a better category discrimination in an intended application. This tool is an open-source software written in MATLAB and made compatible with MathWorks Classification Learner app for further classification purposes such as model training, cross-validation scheme farming, and classification result computation.
Shuangjun Liu, Yu Yin, and Sarah Ostadabbas IEEE Journal of Translational Engineering in Health and Medicine (JTEHM), 2019 AbstractarXivCodeProject
In-Bed Pose Estimation: Deep Learning with Shallow Dataset.
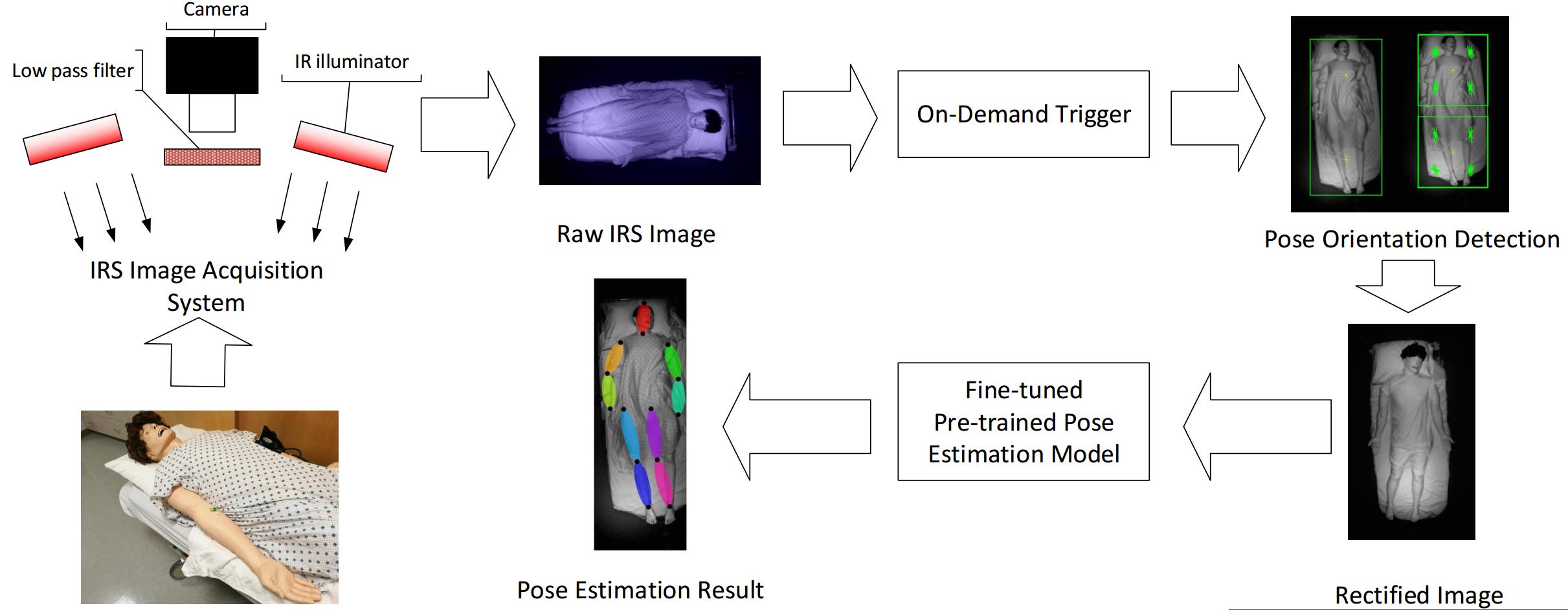
This paper presents a robust human posture and body parts detection method under a specific application scenario, in-bed pose estimation. Although human pose estimation for various computer vision (CV) applications has been studied extensively in the last few decades, yet in-bed pose estimation using camera-based vision methods has been ignored by the CV community because it is assumed to be identical to the general purpose pose estimation methods. However, in-bed pose estimation has its own specialized aspects and comes with specific challenges including the notable differences in lighting conditions throughout a day and also having different pose distribution from the common human surveillance viewpoint. In this paper, we demonstrate that these challenges significantly lessen the effectiveness of existing general purpose pose estimation models. In order to address the lighting variation challenge, infrared selective (IRS) image acquisition technique is proposed to provide uniform quality data under various lighting conditions. In addition, to deal with unconventional pose perspective, a 2-end histogram of oriented gradient (HOG) rectification method is presented. Deep learning framework proves to be the most effective model in human pose estimation, however the lack of large public dataset for in-bed poses prevents us from using a large network from scratch. In this work, we explored the idea of employing a pre-trained convolutional neural network (CNN) model trained on large public datasets of general human poses and fine-tuning the model using our own shallow (limited in size and different in perspective and color) in-bed IRS dataset. We developed an IRS imaging system and collected IRS image data from several realistic life-size mannequins in a simulated hospital room environment. A pre-trained CNN called convolutional pose machine (CPM) was repurposed for in-bed pose estimation by fine-tuning its specific intermediate layers. Using the HOG rectification method, the pose estimation performance of CPM significantly improved by 26.4% in PCK0.1 (probability of correct keypoint) criteria compared to the model without such rectification. Even testing with only well aligned in-bed pose images, our fine-tuned model still surpassed the traditionally-tuned CNN by another 16.6% increase in pose estimation accuracy.
More previous publications:
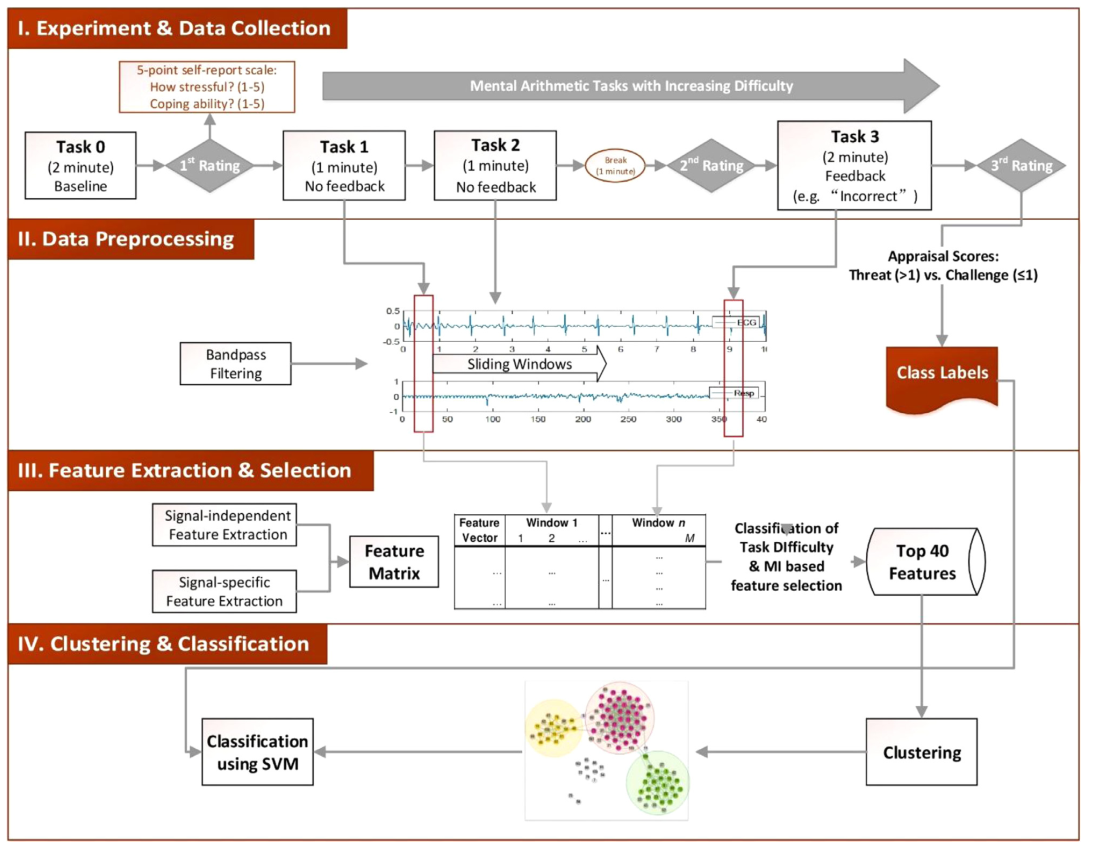
Analysis of Multimodal Physiological Signals Within and Across Individuals to Predict Psychological Threat vs. Challenge
Aya Khalaf, Mohsen Nabian, Miaolin Fan, Yu Yin, Jolie Wormwood, Erika Siegel, Karen S. Quigley, Lisa Feldman Barrett, Murat Akcakaya, Chun-An Chou, and Sarah Ostadabbas
Expert Systems With Applications (ESWA), vol. 140, Feb. 2020. psyarXivAbstract
Analysis of Multimodal Physiological Signals Within and Across Individuals to Predict PsychologicalThreat vs. Challenge.
In this study, we aimed to investigate individual and group-level variations in physiological responding across a series of motivated performance tasks that vary in difficulty. The proposed approach is motivated by documented individual differences in physiological responses observed in motivated performance tasks, such that we first focus on individual differences in physiological responses rather than group-level comparisons. Then, through our analysis of individuals we identify sub-groups (i.e., clusters) of individuals that share common physiological patterns across tasks of varying difficulty and we perform across-subject analysis within each cluster. This is distinct from existing studies which typically do not examine individual vs. subgroup-specific patterns of physiological activity. Such an approach enables us to identify patterns in physiological responses that can be used to predict self-reported judgments of challenge vs. threat with higher accuracy in each subgroup compared to an analysis that includes the entire sample population as a single group. We employed data from an existing experiment in which participants completed three mental arithmetic tasks of increasing difficulty during which different modalities of physiological data were collected. Analyses revealed three subgroups of participants who shared common features that best differentiated their within-individual physiological response patterns across tasks. Support vector machine (SVM) classifiers were trained using both shared features within each group and all computed features to predict challenge vs. threat states. Results showed that, the within-group classification model using group common features achieved higher self-report prediction accuracy compared to an alternative model trained on data from all participants without feature selection.
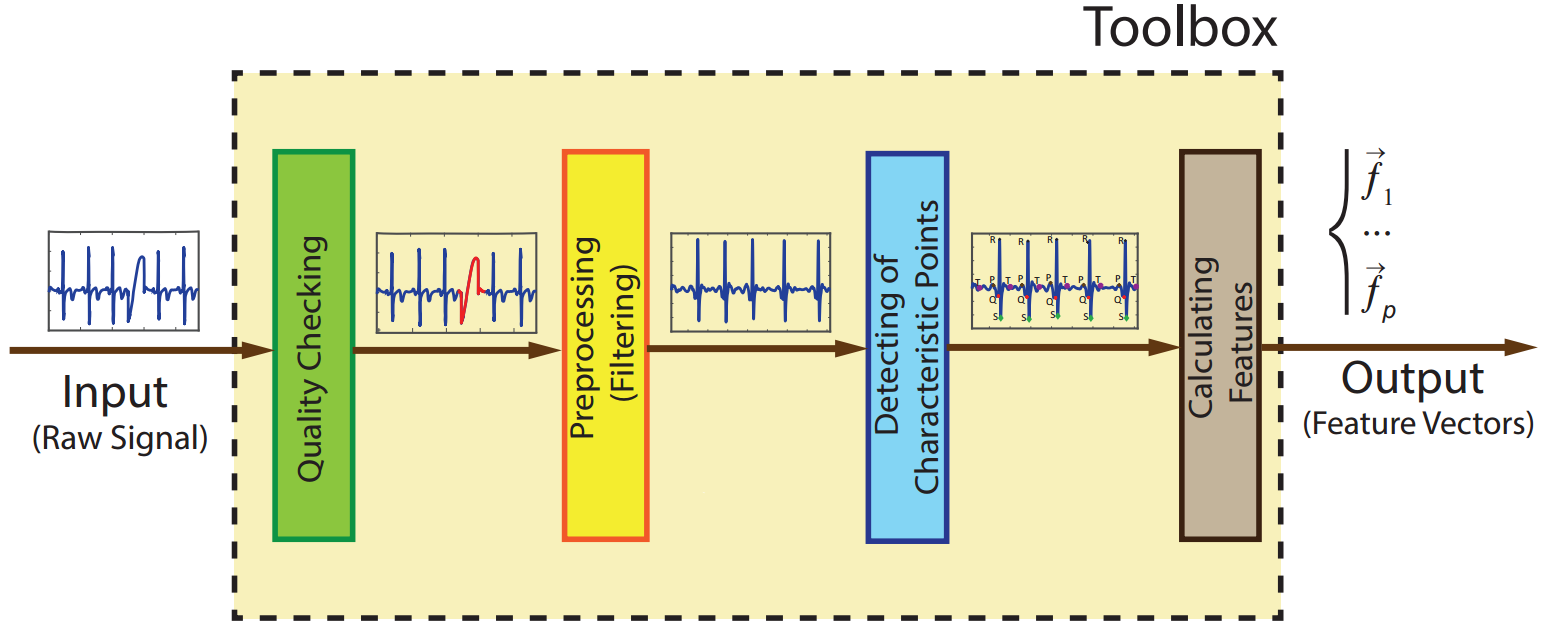
An Open-Source Feature Extraction Tool for the Analysis of Peripheral Physiological Data
Mohsen Nabian, Yu Yin, Jolie Wormwood, Karen S. Quigley, Lisa F. Barrett, and Sarah Ostadabbas
IEEE Journal of Translational Engineering in Health and Medicine (JTEHM), vol. 6, Oct. 2019. PDFAbstractMatlab Code
An Open-Source Feature Extraction Tool for the Analysis of Peripheral Physiological Data.
Electrocardiogram (ECG), Electrodermal Activity (EDA), Electromyogram (EMG), continuous Blood Pressure (BP) and Impedance Cardiography (ICG) are among the physiological signals widely used in various biomedical applications including health tracking, sleep quality assessment, early disease detection/diagnosis, telemedicine and human affective state recognition. This paper presents the development of a biosignal-specific tool for processing and feature extraction of these physiological signals according to state-of-the-art studies reported in the scientific literature and feedback received from field experts. This tool is intended to assist researchers in affective computing, machine learning, and pattern recognition to extract the physiological features from these biosignals automatically and reliably. In this paper, we provide algorithms for signal-specific quality checking, filtering, and segmentation as well as the extraction of features that have been shown to be highly relevant to category discrimination in biomedical and affective computing applications. This tool is an open-source software written in MATLAB and a graphical user interface (GUI) is also provided for the convenience of the users. The GUI is compatible with MathWorks Classification Learner app for further *classification purposes such as model training, cross-validation scheme farming, and classification result computation.